Инструкция к плагину A-feed
Содержание:
- ОБЩАЯ ИНФОРМАЦИЯ
- ИСТОЧНИК ДАННЫХ
- РАБОТА С ОБЛАСТЬЮ КОНТЕНТА RSS-ЛЕНТЫ И ПО ПРЯМОЙ ССЫЛКЕ
- РАБОТА С ОБЛАСТЬЮ КОНТЕНТА, ЕСЛИ В КАЧЕСТВЕ ИСТОЧНИКА ДАННЫХ ВЫБРАНА ЛЕНТА НОВОСТЕЙ
- ПРОДВИНУТАЯ РАБОТА С ОБЛАСТЬЮ КОНТЕНТА
- ПЕРЕЗАПИСЬ ИМПОРТИРУЕМЫХ ПОСТОВ ИЗ ИСТОЧНИКА
- НАСТРОЙКА РЕЖИМА АВТОМАТИЧЕСКОГО ОБНОВЛЕНИЯ
- НАСТРОЙКА ПЕРЕВОДА ЧЕРЕЗ ЯНДЕКС.ОБЛАКО
- НАСТРОЙКА ПЕРЕВОДА ЧЕРЕЗ GOOGLE
Что-то не получается? Воспользоваться услугой технической консультацией.
Программист подключится к вашему сайту и настроит работу A-Feed. Стоимость данной услуги – $100/час.
ОБЩАЯ ИНФОРМАЦИЯ
Начиная с версии A-Feed 2.0.1 импортировать данные можно не только из RSS-лент, но и с обычных страниц сайтов.
Прежде чем приступить к выбору источника, обратите внимание на ряд важных условий и ограничений, с которыми вы можете столкнуться в процессе работы:
- Всегда старайтесь размещать плагин на своем сертифицированном SSL (https) сайте, чтобы не получать исключения по безопасности.
Например
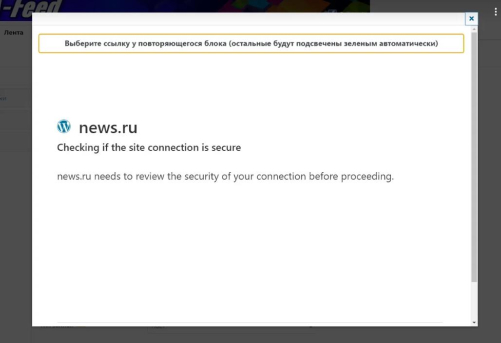
Многие сайты не будут доверять вашему источнику без подтвержденного сертификата по безопасности.
- НЕ ВСЕ источники поддаются обработке. Ссылка может вернуть пустой результат, или в доступе отказано или подозрительный ресурс на этапе выбора в «Источник данных».
Пример сайта, который молча игнорирует запросы, определив что это не человек:

- Имейте в виду что некоторые сайты могут долго отвечать по причине высоконагруженности. Проверяйте их перед этим в браузере.
- Некоторые сайты могут динамично менять данные и на момент парсинга в логах можно увидеть ошибку «EMPTY CONTENT» хотя сам url и открывается в браузере, т.е. то появляется то исчезает, это в пределах нормы.
ИСТОЧНИК ДАННЫХ
В настройках существует три варианта выбора источника:
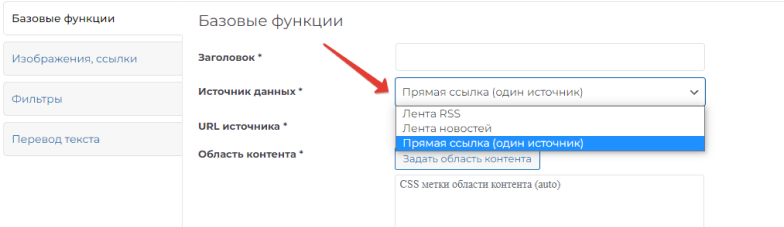
- Лента RSS – данные копируются из RSS-ленты. В качестве адреса необходимо вводить адрес RSS-фида.
- Лента новостей - данные берутся со страницы сайта-донора, где аккумулируются однотипные статьи. Например, страница “Новости”. В этом случае в поле URL вводится ссылка на данный раздел.
- Прямая ссылка (один источник) – парсится лишь единственная страница сайта. Вводится URL данной страницы.
РАБОТА С ОБЛАСТЬЮ КОНТЕНТА RSS-ЛЕНТЫ И ПО ПРЯМОЙ ССЫЛКЕ
Укажите источник (адрес RSS-ленты или адрес страницы). Нажмите кнопку "Задать область контента":
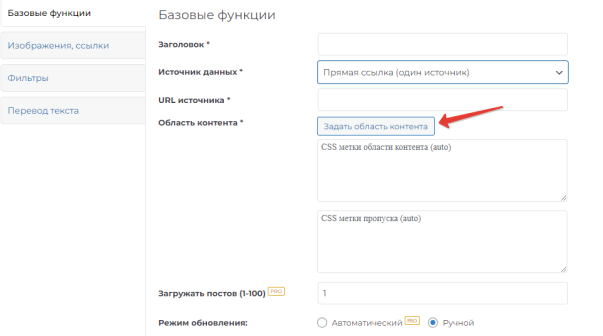
Далее в открывшемся окне необходимо выбрать блоки, которые будут скопированы. Они выделяются зеленым цветом. И повторным кликом - те области, которые необходимо исключить из парсинга. Эти зоны выделяются красным:
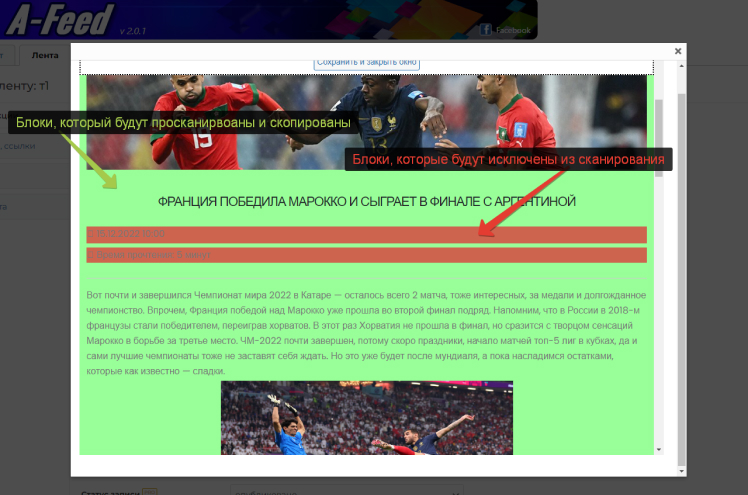
При успешной обработке источника будет подгружен контент ленты, в которой кликом мышки мы сначала задаем основную область, подсвеченную зеленым светом и при необходимости блоки исключения, подсвеченную красным.
Повторный клик на ранее выбранную область - отменяет ее выделение. При клике по зеленой зоне будут отменены и ранее заданные в ней игнорируемые области.
Блоки исключения могут располагаться только в основной области. Таких блоков может быть несколько.
Следует учитывать, что некоторые блоки загруженного сайта которые вы пометили как игнорируемые, могут быть созданы динамически и при импортировании не обрабатываться. Т.к. при каждом запросе блок меняет свои ключевые данные. Либо область может иметь фиксированную разметку без наличия классов и идентификаторов, что также может помешать их пропуску при импорте.
Старайтесь выбрать основную область не во всю ширину сайта - а в максимально близком расположении к требуемому вам контенту.
РАБОТА С ОБЛАСТЬЮ КОНТЕНТА, ЕСЛИ В КАЧЕСТВЕ ИСТОЧНИКА ДАННЫХ ВЫБРАНА ЛЕНТА НОВОСТЕЙ
Как уже написано выше, в качестве URL необходимо указать ссылку на страницу, где собраны необходимые для парсинга записи. Их должно фактически быть не менее двух на странице.
Структура такой страницы должна быть такой:
Анонс1 далее
Анонс2 далее
и т.д.
При нажатии на кнопку “Задать область контента” откроется страница со списком таких записей. Необходимо выбрать одну любую ссылку на продолжение данной записи. Это может быть клик по “Далее”, по изображению или заголовку записи, если они являются ссылками на саму запись.
Выбранные блоки выделяться автоматически:
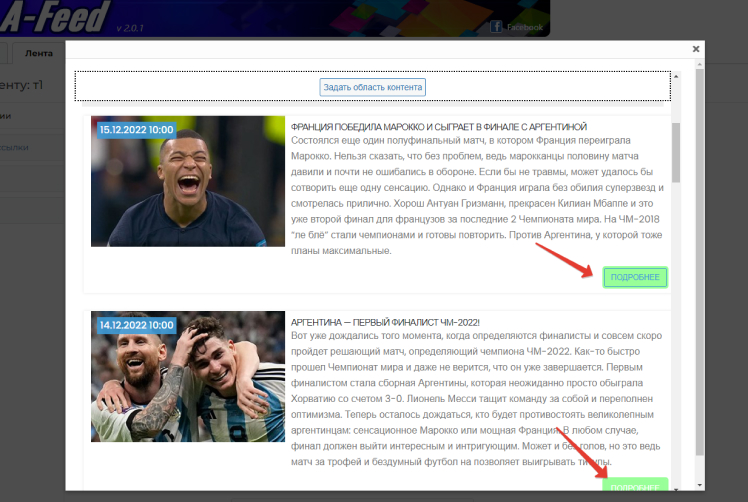
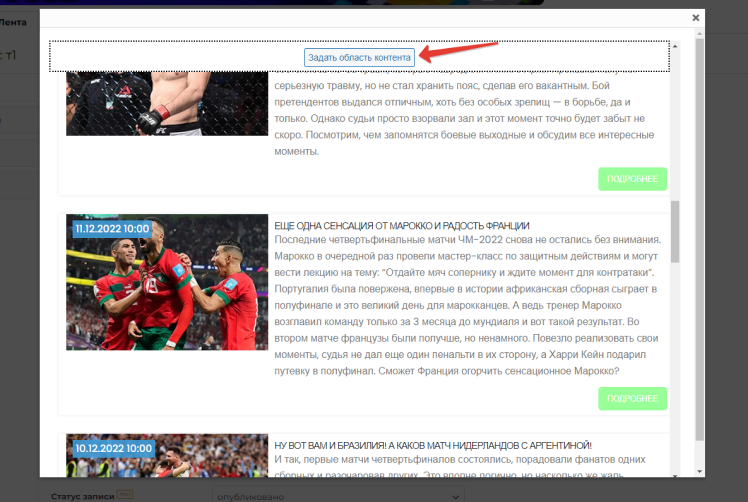
Откроется одна из записей. В ней необходимо выделить требуемые для парсинга области и исключить те, которые сканировать не надо. Так же как в случае с RSS-лентой или отдельной статьей. После чего нажать на кнопку “Сохранить и закрыть”:
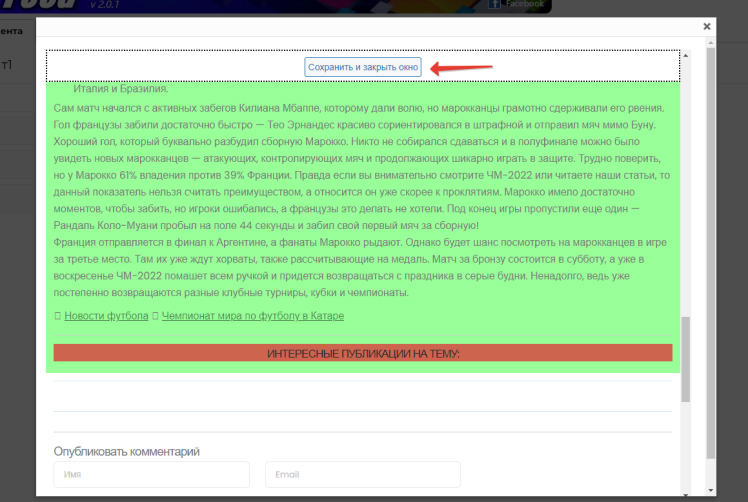
ПРОДВИНУТАЯ РАБОТА С ОБЛАСТЬЮ КОНТЕНТА
Рекомендации из этот раздела помогут вам более точно выбирать ту область контента исходной страницы, которая более точно подходит под нужды вашего сайта. Приступайте к рекомендациям ниже только в том случае, если уверены в том, что вы делаете, так как некоторые действия могут привести к ошибкам.
При предварительном просмотре — всегда проверьте разные страницы:
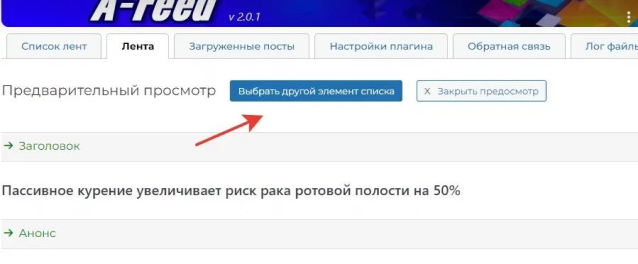
что парсятся нормально.
Если остальные страницы или все из них дают пустой результат:
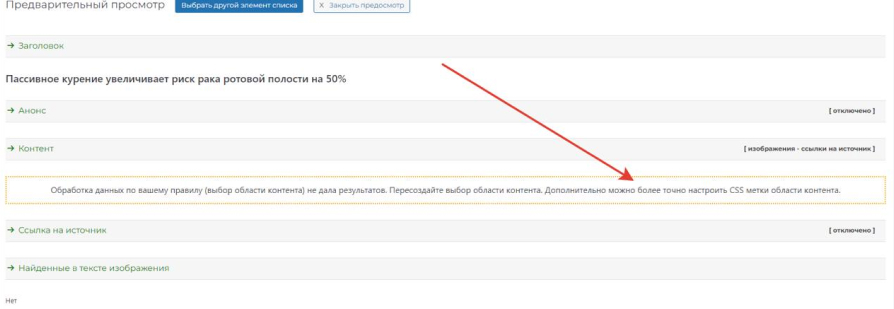
то можно настроить «CSS метки области контента» как пример выглядит так, образец:
//div[@id="content"]/div[@class="xfolkentry"]/div[contains(@class, "description xfolkentryDesc")]
Оно обрабатывается по правилам XPATH (можно дать ссылку).
- - Правило всегда начинается с // (первый корневой элемент)
-
- далее div[@id="content"] это значит тег с атрибутом id="наиемнование/я" (может быть любой иной атрибут)
- - далее разделитель / косая черта говорит о том что следуют вложенный следующий элемент и т.д.
т.е. получается наша зеленая область выбора задается этим правилом, вот пример кода на выше приведенные данные:
<div id="content">
<div id="xfolkentry">
<div id="description xfolkentryDesc">
… Это наши данные которые мы извлекаем ...
</div>
</div>
</div>
Просмотреть этот код у страницы можно нажав в браузере инспектор кода:
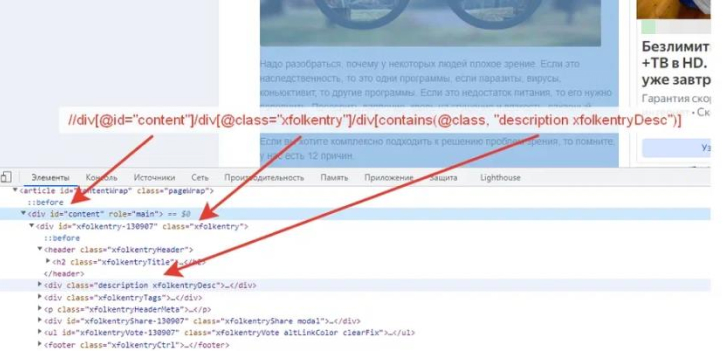
Так вот в некоторых случаях можно более точно поймать необходимый блок удалив в правиле блок(и)
/наименование_тега[атрибуты]
например удалим крайний правый из образца:
//div[@id="content"]/div[@class="xfolkentry"]
или например сократим правило удалив из образца первые два блока:
//div[contains(@class, "description xfolkentryDesc")]
Не забываем что весь блок всегда начинается с двух косых линий //
Также внутренние наименования тоже можно менять/удалять
например как не правильно (пустых быть не должно)
//div[@id=""]/div[@class="xfolkentry"]
или так
//div[@id="content"]/div[@class=""]
Система удаляет автоматически при разборе такие пусты блоки.
Вот пример изменения атрибутов образца:
//div[@id="content"]/div[@class="xfolkentry"]/div[contains(@class, "я_изменил xfolkentryDesc")]
Вот пример кода который не может извлекать данные страниц,
//div[@id="container"]/div[@class="l-gradient-wrapper page-12987"]/div[@class="g-middle"]/div[@class="g-middle-i"]/div[contains(@class, "news-content js-scrolling-area")]/div[@class="news-wrapper"]/div[@class="news-posts"]/div[@class="news-container"]
Обратите внимание на атрибут "page-12987". В нашем примере он указывает что класс является явно динамичным для каждой новой страницы и правило работать не будет, так как он будет изменен. Что можно сделать:
//div[@class="g-middle"]/div[@class="g-middle-i"]/div[contains(@class, "news-content js-scrolling-area")]/div[@class="news-wrapper"]/div[@class="news-posts"]/div[@class="news-container"]
вариант 1: удаляем от начала сам блок и все его предыдущие, пример что получится:
//div[@class="g-middle"]/div[@class="g-middle-i"]/div[contains(@class, "news-content js-scrolling-area")]/div[@class="news-wrapper"]/div[@class="news-posts"]/div[@class="news-container"]
вариант 2: удаляем от хвоста все конечные и сам проблемный блок, пример что получится:
//div[@id="container"]
При втором варианте парсер будет “жадным” — т.к. в этом блоке могут быть и другие блоки — реклама, колонки, виджеты и прочее. И обычно информации попадает больше в область копирования.
ПЕРЕЗАПИСЬ ИМПОРТИРУЕМЫХ ПОСТОВ ИЗ ИСТОЧНИКА
Данные настройки изменяются в пункте “Полученные данные” и имеют 4 варианта:
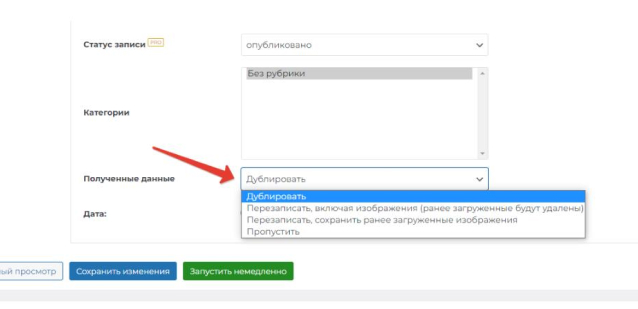
- Дублировать. В этом режиме, если плагин A-Feed во время сканирования встречает запись с аналогичным названием, он создает ее дубль.
- Перезаписать, включая изображения. Вся запись будет полностью перезаписана. В том числе все изображения в ней. Если вручную были добавлены какие-то новые изображения, они будут удалены.
- Перезаписать, сохранив ранее загруженные изображения. Аналогично предыдущему пункту, но изображения будут сохранены. Этот пункт обеспечивает равномерное и классическое наполнение вашего сайта, без создания дублей.
- Пропустить. Если A-Feed находит в источнике заголовок записи, аналогичный тому, который есть на вашем сайте, он пропускает такую запись и переходит к следующей.
По умолчанию плагин стоит в "жадном" режиме, а именно: при каждом новом/повторном запуске парсинга ленты или работы автоматического режима - будут создаваться дубликаты постов. При этом учитывается и сравнивается только лишь заголовок документа.
НАСТРОЙКА РЕЖИМА АВТОМАТИЧЕСКОГО ОБНОВЛЕНИЯ
Приведенные примеры взяты на основе настроек хостинга сайтов BEGET. Подобные настройки имеются на подавляющем большинстве хостинговых площадок.
Необходимо на вашем хостинге запустить задачу по расписанию (crontab).
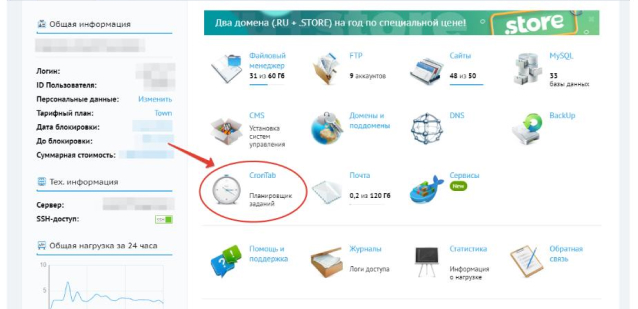
Требования плагина по времени - исполнение каждые 10-15 минут.
Можно задавать через планировщик заданий:
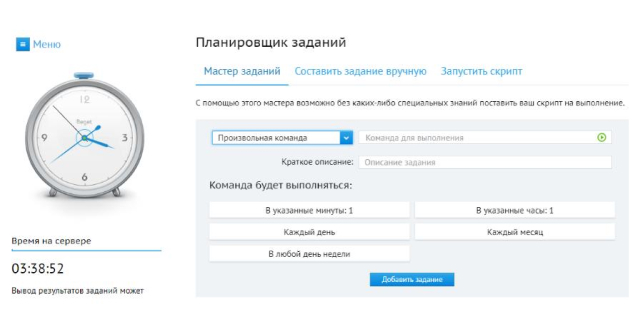
А можно и командой. Пример команды на каждые 10 минут:
*/10 * * * *
Сама команда для выполнения:
/usr/bin/wget -qO- ваш_домен/wp-content/plugins/afeed/auto.php?crontab=afeed
Где ваш_домен - это домен на котором установлен плагин.
Пример c указанием домена, где в качестве домена выбран наш тестовый сайт https://a-feed-sample.com/ , где можно посмотреть на то, как работает плагин A-Feed в боевых условиях:
/usr/bin/wget -qO- a-feed-sample.com/wp-content/plugins/afeed/auto.php?crontab=afeed
Вот так это выглядит в панеле управления сайтом на хостинге:
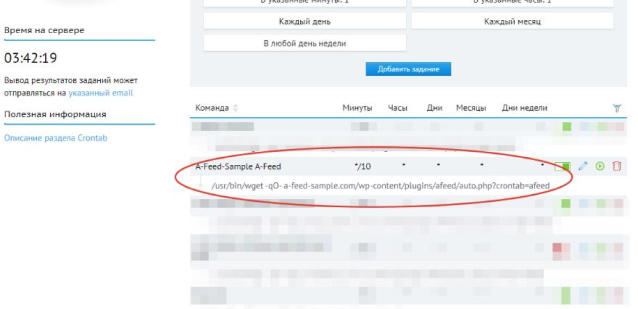
В случае проблем с выполнением - обратитесь в техническую поддержку вашего хостинга.
НАСТРОЙКА ПЕРЕВОДА ЧЕРЕЗ ЯНДЕКС.ОБЛАКО
Для получения OAUTH токена и ключа папки сервиса вы должны иметь свой аккаунт в yandex.ru
- Заведите аккаунт Яндекс и войдите в него
- Перейдите по ссылке: https://cloud.yandex.ru/docs/iam/concepts/authorization/oauth-token
- В предложении "Получить OAuth-токен для работы с Yandex Cloud можно с помощью ЗАПРОСА к сервису Яндекс.OAuth" нажмете на ссылку "ЗАПРОСА" и получите OAUTH:
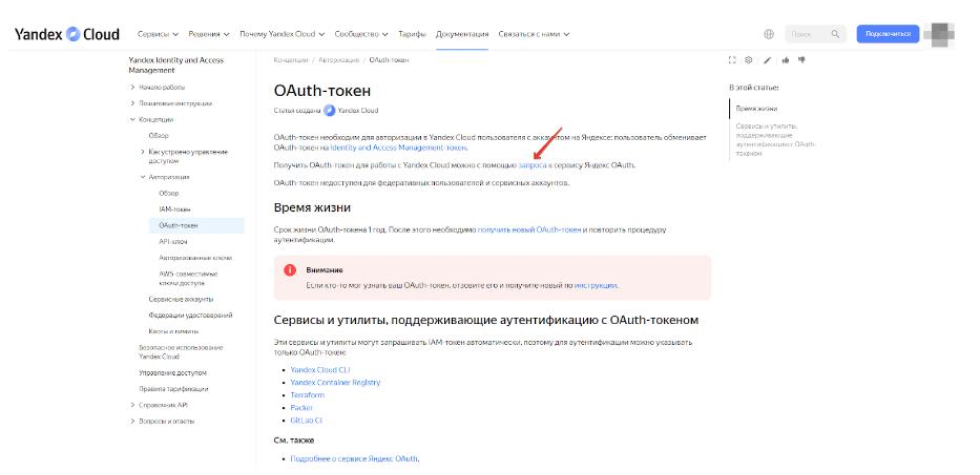
Полученный OAUTH будет выглядеть вот так:

Пустая страница и на ней только ваш OAUTH ключ, ничего больше.
- Активируйте платный аккаукт следуя инструкциям Яндекс. Не забудьте пополнить баланс.
- Потом перейдите по ссылке https://cloud.yandex.ru/ кнопка "консоль"
- Перейти:
- Далее необходимо выбрать "Cоздать каталог":
Необходимо создать каталог с любым допустимым именем.
- Скопировать ключ папки сервиса:
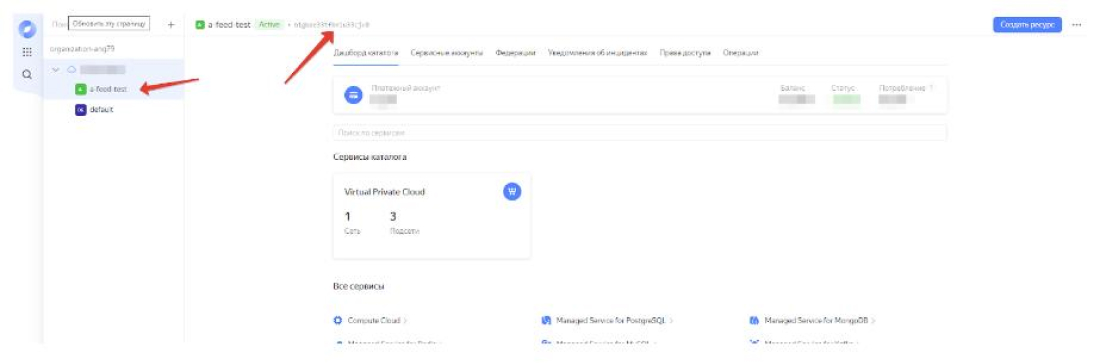
Полученные OAUTH и ключ папки сервиса необходимо ввести в соответствующие поля настройки плагина A-Feed:

НАСТРОЙКА ПЕРЕВОДА ЧЕРЕЗ GOOGLE
- Заведите аккаунт Google и войдите в него
- Перейти в консоль Google.Cloud по этой ссылке: https://console.cloud.google.com/
- Выбираете проект, а потом в открывшемся окне создаете новый
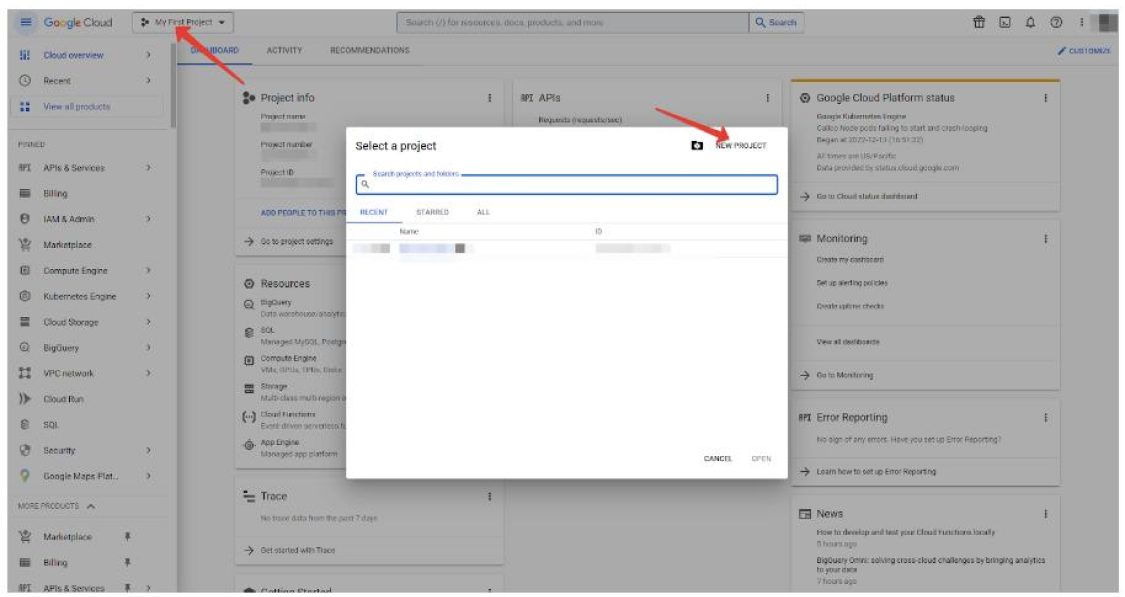
В нашем примере он называется My First Project. Выбираем его (если он после создания не выбран) в окне выбора проектов:
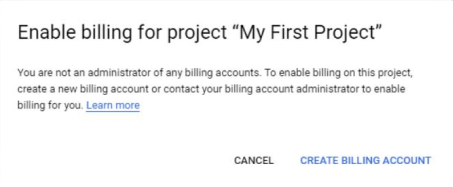
- Подключаем действующую банковскую карту. На ней должны быть средства, обычно списывается и тут же возвращается небольшая сумма в пределах $1 для проверки работоспособности карты. Все это делается в разделе Billing:
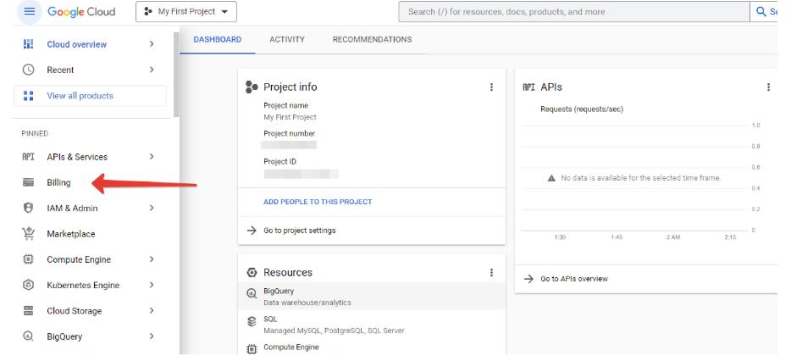
Создаем и привязываем платежный аккаунт:
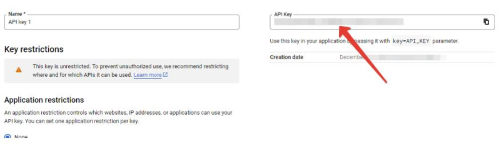
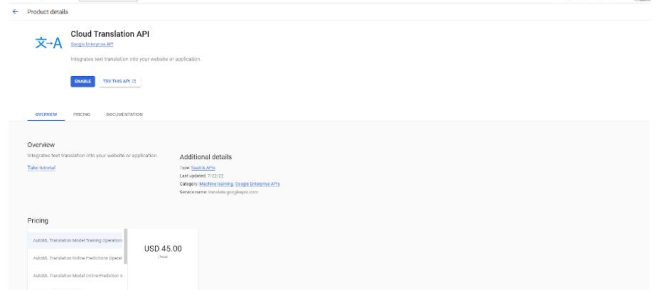
- Остается получить API-ключ для чего необходимо перейти по этой ссылке: https://console.cloud.google.com/apis/library/translate.googleapis.com
- Нажать на кнопку Enable:
- (опционально, этого пункта может не быть) Выбираете свой проект после чего (или сразу) попадаете в консоль управления API, где надо перейти на вкладку “Учетные данные” (“Credentials”):
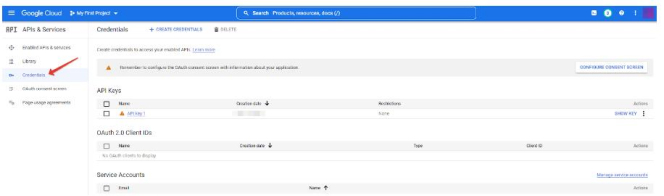
- Остается кликнуть на API-ключ:
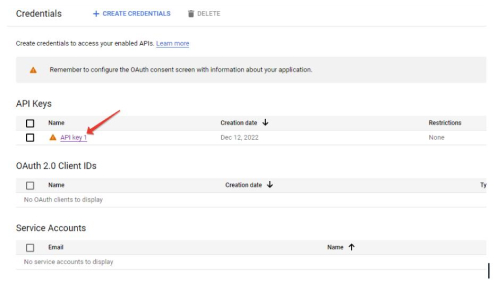
- В новом окне он будет отображен: